
Contents
Come funziona l’algoritmo di Facebook? Una domanda da 1 milione di dollari.
Ogni giorno leggo decine di guide e notizie su tutto quello che accade nel mondo digital.
Spesso sono guide molto utili avvolte meno.
Per questo abbiamo creato il nostro canale Telegram di Confucionet per selezionare le migliori notizie e aggiornamenti inerenti il mondo del web.

Proprio ieri mentre scorrevo le varie notizie dal blog ufficiale di Facebook veniva pubblicato questo post.
How Does News Feed Predict What You Want to See?
di Akos Lada, Data Science Manager, Meihong Wang, Engineering Director, and Tak Yan, Product Management Director di Facebook.
Visto che è una fonte primaria ho deciso di tradurla e pubblicarla direttamente sul nostro blog, per avere una panoramica da una fonte ufficiale su come funziona l’algoritmo di Facebook.
Buona Lettura
In che modo News Feed prevede ciò che desideri vedere?
Quando si tratta dell’algoritmo del feed di notizie, ci sono molte teorie e miti.
La maggior parte delle persone capisce che c’è un algoritmo al lavoro e molti conoscono alcuni dei fattori che informano quell’algoritmo (se ti piace un post o interagisci con esso, ecc.).
Ma ci sono ancora molte cose fraintese.
Condividiamo pubblicamente molti dei dettagli e delle caratteristiche di News Feed.
Ma sotto il cofano, il sistema di classificazione del machine learning (ML) che alimenta News Feed è incredibilmente complesso, con molti livelli.
Stiamo condividendo nuovi dettagli su come funziona il nostro sistema di classificazione e le sfide di costruire un sistema per personalizzare il contenuto per più di 2 miliardi di persone e mostrare a ciascuno di loro contenuti rilevanti e significativi per loro, ogni volta che vengono su Facebook.
Cosa c’è di così difficile in questo?
Innanzitutto, il volume è enorme.
Più di 2 miliardi di persone in tutto il mondo usano Facebook.
Per ciascuna di queste persone, ci sono più di mille post “candidati” (o post che potrebbero potenzialmente apparire nel feed di quella persona).
Ora stiamo parlando di trilioni di post in tutte le persone su Facebook.
Ora considera che per ogni persona su Facebook, ci sono migliaia di segnali che dobbiamo valutare per determinare ciò che quella persona potrebbe trovare più rilevante.
Quindi abbiamo trilioni di post e migliaia di segnali e dobbiamo prevedere immediatamente ciò che ciascuna di queste persone vuole vedere nel proprio feed.
Quando apri Facebook, quel processo avviene in background nel secondo o giù di lì per caricare il tuo feed di notizie.
E una volta che tutto questo funziona, le cose cambiano e dobbiamo tenere conto dei nuovi problemi che sorgono, come il clickbait e la diffusione della disinformazione.
Quando ciò accade, dobbiamo trovare nuove soluzioni.
In realtà, il sistema di classificazione non è solo un singolo algoritmo; sono più livelli di modelli e classifiche ML che applichiamo per prevedere il contenuto più rilevante e significativo per ogni utente.
Man mano che ci spostiamo attraverso ogni fase, il sistema di classificazione restringe quelle migliaia di post candidati alle poche centinaia che appaiono nel feed di notizie di qualcuno in un dato momento.
Come funziona?
In parole povere, il sistema determina quali post vengono visualizzati nel tuo feed di notizie e in quale ordine, prevedendo ciò che è più probabile che ti interessi o che ti impegni.
Queste previsioni si basano su una varietà di fattori, inclusi cosa e chi hai seguito, apprezzato o con cui hai interagito di recente.
Per capire come funziona in pratica, iniziamo con cosa succede a una persona che accede a Facebook: lo chiameremo Juan.
Dall’accesso di Juan ieri, il suo amico Wei ha pubblicato una foto del suo cocker spaniel.
Un’altra amica, Saanvi, ha pubblicato un video della sua corsa mattutina.
La sua pagina preferita ha pubblicato un interessante articolo sul modo migliore per vedere la Via Lattea di notte, mentre il suo gruppo di cucina preferito ha pubblicato quattro nuove ricette di lievito naturale.
È probabile che tutto questo contenuto sia pertinente o interessante per Juan perché ha scelto di seguire le persone o le pagine che lo condividono.
Per decidere quale di queste cose dovrebbe apparire più in alto nel News Feed di Juan, dobbiamo prevedere ciò che conta di più per lui e quale contenuto ha il valore più alto per lui.
In termini matematici, dobbiamo definire una funzione obiettivo per Juan ed eseguire un’ottimizzazione a singolo obiettivo.
Possiamo usare le caratteristiche di un post, come chi è taggato in una foto e quando è stato pubblicato, per prevedere se a Juan potrebbe piacere .
Ad esempio, se Juan tende a interagire spesso con i post di Saanvi (ad esempio, condividendo o commentando) e il suo video in esecuzione è molto recente, c’è un’alta probabilità che a Juan piaccia il suo post.
Se Juan si è occupato di più contenuti video che foto in passato, la previsione simile per la foto di Wei del suo cocker spaniel potrebbe essere piuttosto bassa.
In questo caso, il nostro algoritmo di classificazione classificherebbe il video in esecuzione di Saanvi più in alto della foto del cane di Wei perché prevede una maggiore probabilità che a Juan piaccia.
Ma il piacere non è l’unico modo in cui le persone esprimono le loro preferenze su Facebook.
Ogni giorno, le persone condividono articoli che trovano interessanti, guardano video di persone o celebrità che seguono o lasciano commenti ponderati sui post dei loro amici.
Matematicamente, le cose diventano più complesse quando dobbiamo ottimizzare per più obiettivi che si sommano al nostro obiettivo principale: creare il valore più a lungo termine per le persone mostrando loro contenuti significativi e rilevanti per loro.
Più modelli ML producono più previsioni per Juan: la probabilità che si impegni con la foto di Wei, il video di Saanvi, l’articolo della Via Lattea o le ricette di lievito naturale. Ogni modello cerca di classificare questi pezzi di contenuto per Juan.
A volte non sono d’accordo: potrebbe esserci una maggiore probabilità che Juan gradisca il video in esecuzione di Saanvi rispetto all’articolo sulla Via Lattea, ma potrebbe essere più propenso a commentare l’articolo che il video.
Quindi abbiamo bisogno di un modo per combinare queste diverse previsioni in un punteggio ottimizzato per il nostro obiettivo primario di valore a lungo termine.
Come possiamo misurare se qualcosa crea valore a lungo termine per una persona? Chiediamo loro.
Ad esempio, intervistiamo le persone per chiedere quanto significativa hanno trovato un’interazione con i loro amici o se un post valeva il loro tempo in modo che il nostro sistema rifletta ciò che le persone dicono di apprezzare e trovano significativo.
Quindi possiamo prendere in considerazione ogni previsione per Juan in base alle azioni che le persone ci dicono (tramite sondaggi) sono più significative e valgono il loro tempo.
Staccare gli strati
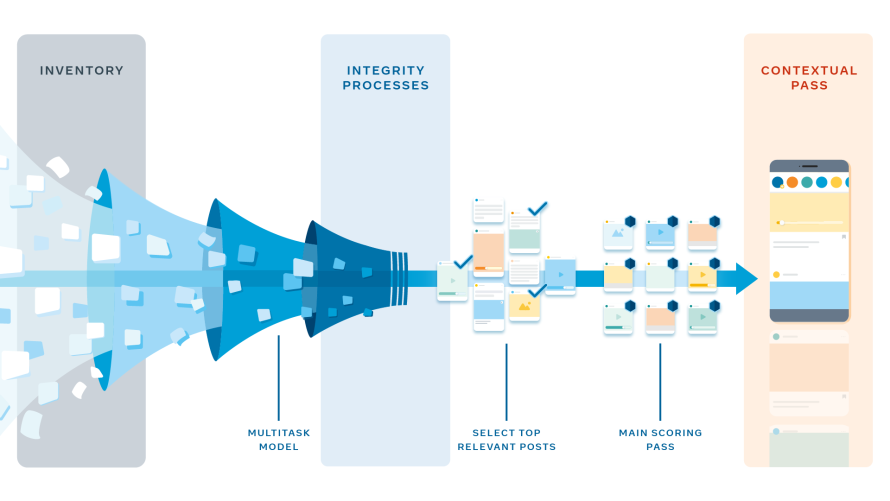
Per classificare più di mille post per utente, al giorno, per più di 2 miliardi di persone – in tempo reale – dobbiamo rendere il processo efficiente.
Lo gestiamo in vari passaggi, organizzati strategicamente per renderlo veloce e per limitare la quantità di risorse di calcolo richieste.
Innanzitutto, il sistema raccoglie tutti i post candidati che possiamo eventualmente classificare per Juan (la foto del cocker spaniel, il video in esecuzione, ecc.).
Questo inventario idoneo include qualsiasi post condiviso con Juan da un amico, un gruppo o una pagina a cui è collegato che è stato creato dall’ultimo accesso e non è stato eliminato.
Ma come dovremmo gestire i post creati prima dell’ultimo accesso di Juan che non ha ancora visto?
Per assicurarci che i post non visti vengano riconsiderati, applichiamo una logica di bumping non letto: i post nuovi che sono stati classificati per Juan (ma non visti da lui) nelle sue sessioni precedenti vengono aggiunti all’inventario idoneo per questa sessione.
Applichiamo anche una logica di blocco delle azioni in modo che tutti i post che Juan ha già visto che da allora abbiano innescato un’interessante conversazione tra i suoi amici vengano aggiunti all’inventario idoneo.
Successivamente, il sistema deve assegnare un punteggio a ogni post per una serie di fattori, come il tipo di post, la somiglianza con altri elementi e quanto il post corrisponde a ciò con cui Juan tende a interagire.
Per calcolare questo valore per più di 1.000 post, per ciascuno dei miliardi di utenti, tutti in tempo reale, eseguiamo questi modelli per tutte le storie candidate in parallelo su più macchine, chiamate predittori.
Prima di combinare tutte queste previsioni in un unico punteggio, dobbiamo applicare alcune regole aggiuntive.
Aspettiamo fino a dopo aver ottenuto queste prime previsioni in modo da poter restringere il pool di post da classificare e le applichiamo su più passaggi per risparmiare potenza di calcolo.
Innanzitutto, a ogni post vengono applicati determinati processi di integrità.
Questi sono progettati per determinare quali misure di rilevamento dell’integrità, se presenti, devono essere applicate alle storie selezionate per la classificazione.
Nel passaggio successivo, un modello leggero restringe il pool di candidati a circa 500 dei posti più rilevanti per Juan.
La classificazione di meno storie ci consente di utilizzare modelli di rete neurale più potenti per i passaggi successivi.
Il prossimo è il passaggio di punteggio principale, dove avviene la maggior parte della personalizzazione.
Qui, un punteggio per ogni storia viene calcolato in modo indipendente, quindi tutti i 500 post vengono ordinati in base al punteggio.
Per alcuni, il punteggio potrebbe essere più alto per i Mi piace che per i commenti, poiché ad alcune persone piace esprimersi più piacendo che commentando.
Qualsiasi azione in cui una persona si impegna raramente (ad esempio, una previsione simile che è molto vicina allo zero) ottiene automaticamente un ruolo minimo nel ranking, poiché il valore previsto è molto basso.
Infine, eseguiamo il passaggio contestuale, in cui vengono aggiunte funzionalità contestuali come le regole di diversità del tipo di contenuto per assicurarci che il feed di notizie di Juan abbia un buon mix di tipi di contenuto e non vede più post video, uno dopo l’altro.
Tutti questi passaggi di classificazione avvengono nel tempo necessario a Juan per aprire l’app di Facebook e, in pochi secondi, ha un feed di notizie con punteggio pronto per essere sfogliato e apprezzato.
Fonte: How Does News Feed Predict What You Want to See?

- Guida Canva - Settembre 29, 2021
- Google July 2021 Core Update - Luglio 15, 2021
- Link building SEO cos’è? Guida passo passo - Luglio 10, 2021

Una panoramica su come funziona l’algoritmo di Facebook ripresa da fonte Ufficiale.